概要
N個のジョブがあるとします。番目のジョブは実行時間に
だけ要するとします。これをノード数mのクラスターコンピュータに投げるとき、どのようにジョブスケジュールを割り振れば、クラスターのノードの実行時間の最大を最小にできるでしょうか。
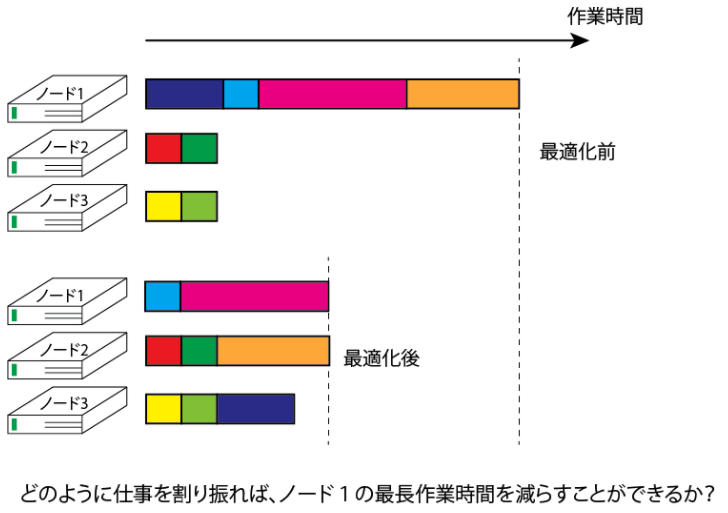
直感的な実装数理モデル
問題の定式化
先ほど概要で説明したことを数式にしましょう。
ノード番目のジョブの集合を
とすると、
ノード番目の作業時間の合計は
となります。そして問題は
となる組合せを探すことになります。ここでジョブの総実行時間が最大となるノードを1としても一般性を失わないため、以降ではノード1の総実行時間を最小化することを考えましょう。ちなみに、この問題はNP困難であることが知られています。
バイナリ変数
最適化に使用するバイナリ変数を、ノードでジョブ
を行うとき
、それ以外ならば0と定義します。
またをノード1とノード
の仕事量の差
を表す変数とします。具体的には
のとき
、それ以外のとき0と定義します。
それぞれのジョブに対するone-hot encoding
あるジョブはいずれか一つのノードで実行されなければなりません。よって
となります。
あるノードでの総実行時間に対するone-hot encoding
の定義から、ノード
での総実行時間
とノード1の総実行時間
との差の間に、以下のような関係が成り立たなければなりません。
ここではユーザが指定する変数で、許容されるノード1とノード
の総実行時間の差を表します。また
に対するone-hot encodingも必要になります。
これら制約がないとノード1の総実行時間よりも他のノードでの総実行時間の方が多くなります。
目的関数
最大であるノード1での総実行時間を最小にしたいので、この最適化の目的関数は
です。
QUBOによる表現
上述の制約及び目的関数をQUBOにすると以下のようになります。
ここではハイパーパラメータです。
Log encodingによる補助変数を用いた(*)式第三項の変更
元の数理モデルは以下のようにノード1とノードの総実行時間の差が
以下であるということ、すなわち
というものでした。しかしOpenJijチュートリアルのナップサック問題のページにある通り、これのone-hot encodindを考えると制約の数が増え、冗長になります。よってこの問題をLog encodingにより解決しましょう。を
を超えない最大の整数とします。すると(*)式第三項は
ここでは2進数を表現するために用いた補助のバイナリ変数です。
スクリプト詳解
スクリプト構成
. ├── job_sequencing.py ├── make_energy.py ├── make_instance.py ├── solve_problem.py └── visualize_solution.py
job_sequencing.py
このスクリプト群のmainスクリプトです。各種関数の呼び出しを行います。
import make_energy as me import make_instance as mi import solve_problem as sop import visualize_solution as vs if __name__ == '__main__': # set problem num_nodes, job_length, num_jobs, diff = mi.make_instance() # set costs & constraints model = me.make_energy(num_nodes=num_nodes, job_length=job_length, num_jobs=num_jobs, diff=diff) # set hyper parameters parameters = {'h_a': 5.0, 'h_b': 2.0} # solve with OpenJij solution, broken = sop.solve_problem(model=model, **parameters) # check broken print(broken) print(solution) # visualize result vs.visualize_solution(sol_x=solution['x'], job_length=job_length, num_nodes=num_nodes)
make_instance.py
問題設定を行います。この問題では以下の定義を行なっています。
- num_nodes (int) : 計算ノードの数
- job_length (list) : 計算ノードに割り振るジョブの実行時間
- diff (int) : ノード0と他のノードの総実行時間の差をどこまで許容するかを示した量
import numpy as np def make_instance(): num_nodes = 3 job_length = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) num_jobs = len(job_length) diff = 3 return num_nodes, job_length, num_jobs, diff
make_energy.py
解きたい問題のハミルトニアンを計算しています。ここではPyQUBOを用いてバイナリ変数と2進数エンコーディングによる定式化表現を実現しています。
from pyqubo import Array, Constraint, LogEncInteger, Placeholder def make_energy(num_nodes, job_length, num_jobs, diff): # set placeholder lambda_a = Placeholder('h_a') lambda_b = Placeholder('h_b') # set binary variables x = Array.create('x', shape=(num_jobs, num_nodes), vartype='BINARY') z = LogEncInteger('z', 0, diff) # set objective function obj = sum([job_length[i]*x[i][0] for i in range(num_jobs)]) # set one-hot encoding constraint for jobs x_const = sum([(1-sum([x[i][a] for a in range(num_nodes)]))**2 for i in range(num_jobs)]) h_a = Constraint(x_const, label='h_a') # set sum of execution time constraint y_const = 0 for a in range(1, num_nodes): y_const += (diff-sum([job_length[i]*(x[i][0]-x[i][a]) for i in range(num_jobs)])-z) ** 2 h_b = Constraint(y_const, label='h_b') # compute total energy energy = obj + lambda_a * h_a + lambda_b * h_b # compile model = energy.compile() return model
solve_problem.py
OpenJijのシミュレーテッドアニーリングで最適解を求めています。以下のスクリプトのoj.SASamplerをoj.SQASamplerに変更するだけで、ソルバーをシミュレーテッド量子アニーリングに変更することができます。
import openjij as oj def solve_problem(model, h_a, h_b): # set dictionary of hyper parameters feed_dict = {'h_a': h_a, 'h_b': h_b, } # convert to qubo qubo, offset = model.to_qubo(feed_dict=feed_dict) # solve with OpenJij (SA) num_reads = 100 sampler = oj.SASampler(num_reads=num_reads) response = sampler.sample_qubo(Q=qubo) # take mininum state dict_solution = response.first.sample # decode for analysis solution, broken, energy = model.decode_solution(dict_solution, vartype='BINARY', feed_dict=feed_dict) return solution, broken
visualize_solution.py
得られた解をmatplotlibで可視化しています。
import math import matplotlib.pyplot as plt def visualize_solution(sol_x, job_length, num_nodes): exec_time = [0] * num_nodes for i in range(len(job_length)): for a in range(num_nodes): exec_time[a] += sol_x[i][a] * job_length[i] yint = range(0, math.ceil(max(exec_time))+1, 2) names = ['node '+str(a) for a in range(num_nodes)] plt.bar(names, exec_time) plt.yticks(yint) plt.show()
可視化結果
以下に計算ノードの数は3ノード、ジョブの数を10個とし、それぞれの実行時間を[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]とします。
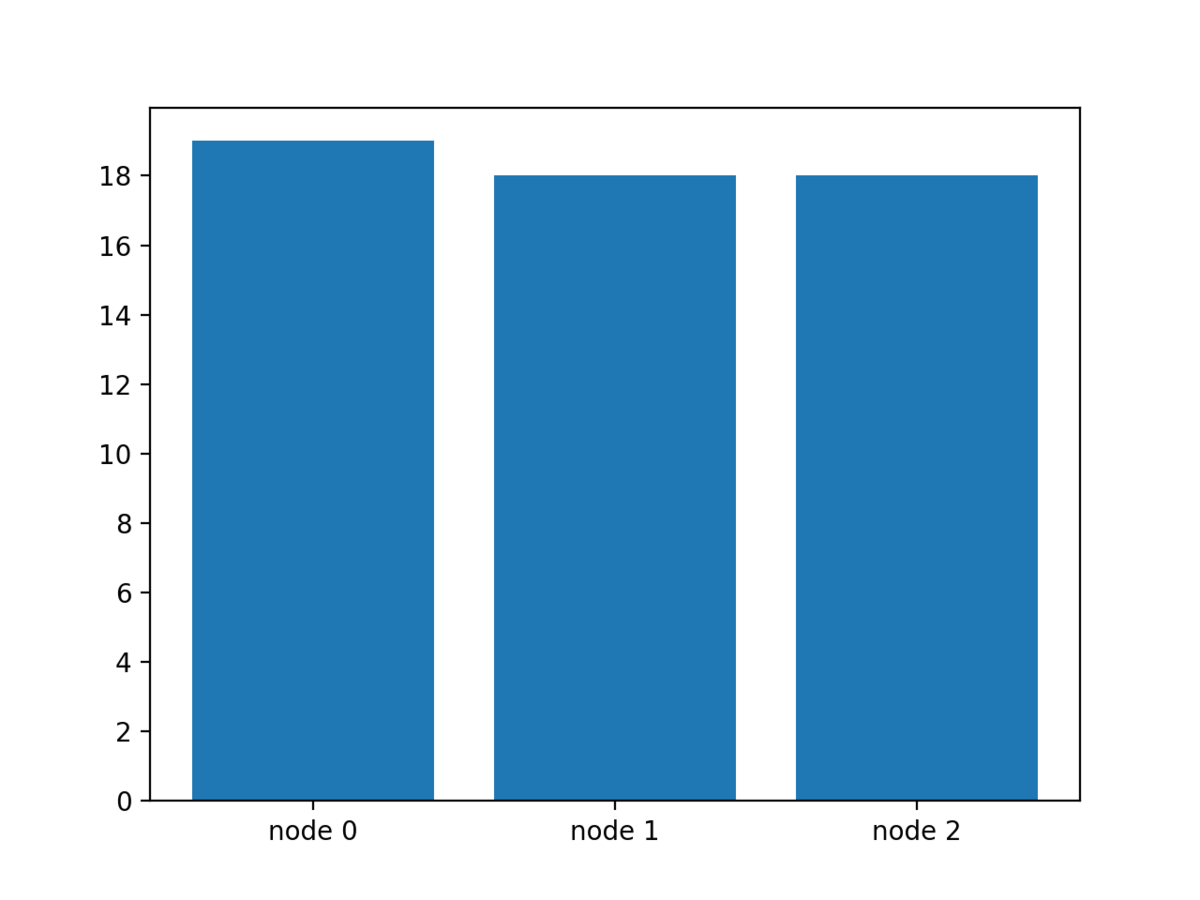
ジョブが3つの計算ノードに分散され、最大であるノード0の実行時間が最小になっていることがわかります。
結言
今回は整数長ジョブスケジューリング問題を解くための、数理モデル・定式化の考え方、そしてOpenJijを用いた実際のスクリプト例をご紹介いたしました。OpenJijチュートリアルではこのほかの問題例も掲載しています。ぜひインストールしてみてください。弊社Jijではこのような最適化問題を軸として、社会の計算困難を解決するべく日々奮闘しています。