この記事の概要
Googleのページ検索において重要な技術にページランクアルゴリズムがあります。この記事はその概要と、そのページランクを断熱量子計算で高速に求める手法をご紹介します。
Google行列
ページ間リンク
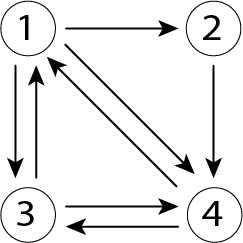
上図ように、ページ1からはページ2, 3, 4へのリンク、ページ2からはページ4へのリンク、ページ3からはページ1, 4へのリンク、そしてページ4からはページ1, 3へのリンクがそれぞれ貼られているとします。このときどのページが重要度が高いでしょうか、というのがページランクアルゴリズムで求めたい答えです。
このとき
- (1, 2), (1, 3), (1, 4)の3本をエッジとして持つ => d(1) = 3
- (2, 4)の1本をエッジとして持つ => d(2) = 1
- (3, 1), (3, 4)の2本をエッジとして持つ => d(3) = 2
- (4, 1), (4, 3)の2本をエッジとして持つ => d(2) = 2
よりこのリンク情報を以下のようにページ数xページ数の隣接行列で表現します。
より一般的に記述するとは以下のようになります。
イテレーションによるページランクベクトルの計算
初期に全てのページの重要度が等しくとしましょう。これをページランクベクトルと呼びます。ここに隣接行列
をかけることで、そのページがどの程度他のページと関わりがあり重要であるかがわかります。これを繰り返し作用させることで値が収束し、最終的なページ重要度を得ることができます。
ここでは行列の転置を表します。実際に上の例でこれを計算すると以下のように値が収束していきます。
| iteration回数 | 1 | 2 | 3 | 4 |
| 0 | 0.25 | 0.25 | 0.25 | 0.25 |
| 5 | 0.299 | 0.100 | 0.267 | 0.332 |
| 10 | 0.3 | 0.1 | 0.266 | 0.333 |
よってこの例ではページ4が最も重要であることがわかります。これは他のページに比べて、ページ4に入ってくるリンクの数が3つで一番多いことに起因しています。
ぶら下がりページ(dangling nodes)の扱い方
下図のページ4のように、他のページからリンクが貼られていてもそこから先にはページが貼られていないようなページのことをぶら下がりページと呼びます。
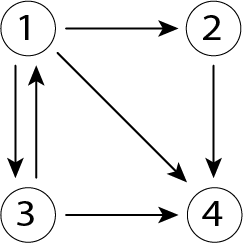
上述の議論からこのグラフの隣接行列は
となります。これを用いて繰り返し計算を行ってみましょう。すると
| iteration回数 | 1 | 2 | 3 | 4 |
| 0 | 0.25 | 0.25 | 0.25 | 0.25 |
| 5 | 0.001 | 0.001 | 0.001 | 0.004 |
のように全ての成分が0に収束するようになり、正しくページランクベクトルを計算することができません。よってこれを回避するために、ある行の成分が全て0の場合はページ数分の1、すなわちを代わりに入力します。この行列を
とすると
このとき
の値の収束を見てみましょう。
| iteration回数 | 1 | 2 | 3 | 4 |
| 0 | 0.25 | 0.25 | 0.25 | 0.25 |
| 5 | 0.200 | 0.178 | 0.178 | 0.442 |
| 30 | 0.2 | 0.177 | 0.177 | 0.444 |
のようになりました。このことから3ページからリンクが貼られているページ4が最も重要であることがわかります。
可約グラフがある場合とGoogle行列
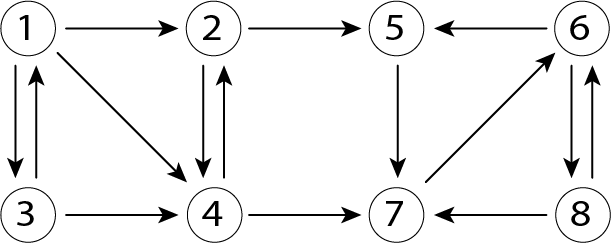
上図のようなグラフの場合、リンクの情報を表す隣接行列は以下のようになります。
しかし実際のこれを使って繰り返し計算を行ってページランクベクトルを計算すると
| iteration回数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 0 | 0.125 | 0.125 | 0.125 | 0.125 | 0.125 | 0.125 | 0.125 | 0.125 |
| 30 | 0.000 | 0.000 | 0.000 | 0.000 | 0.102 | 0.364 | 0.273 | 0.182 |
のように、1~4までの重要度が0に収束します。元のグラフをみてみると、ページ4はページ1, 2, 3からリンクされているため、本来ならば0でない重要度になってほしいところです。
この例は実は可約グラフ(reducible graph)になっており、このままではページランクベクトルを正しく計算することはできません。
そこでBrin & Page 1998では以下のように隣接行列に修正を加え、これをGoogle行列と定義しました。
ここでです。
は"Personalization vector"と呼ばれる確率分布を表します。よく用いられるのは、全ての分布を等しく
としたものです。
は全ての要素が1のベクトルです。
は、グラフにしたがって別のページへと遷移する確率を表すパラメータです。すなわちこの式は
の確率分布にしたがって、
程度はランダムなページ遷移を許容することを意味します(Googleが用いている値は
)。
簡単のため、上述のよく用いられる例でGoogle行列を書き直してみましょう。
これを用いてページランクベクトルの収束をみてみましょう。
| iteration回数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 0 | 0.125 | 0.125 | 0.125 | 0.125 | 0.125 | 0.125 | 0.125 | 0.125 |
| 30 | 0.030 | 0.054 | 0.027 | 0.062 | 0.162 | 0.284 | 0.242 | 0.139 |
先ほどの指摘通り、ページ1~4の値が0でない有限の値に収束しています。
断熱量子計算
ハミルトニアンとエネルギーギャップ
ハミルトニアン
アニーリング終状態のハミルトニアンをとします。すると
のようになります。ここで最終的に求めたいページランクベクトルを思い出しましょう。
はその導出方法から、
の固有値1の固有ベクトルであることがわかります。よって、求める終状態は
のように書くことができます。
同様の形で、アニーリング開始時のハミルトニアンを
のように定義します。ここでは先ほどのGoogle行列を全結合グラフにした場合のものです。この場合、全てのページ重要度が等しくなるはずなので、量子アニーリングの初期に準備する
の基底状態は
となります。ここではページ
がページ重要度1の状態です。
これらを用いて、量子アニーリングを行う際に用いるハミルトニアンは、時間発展を表す]を用いて
と書けます。
エネルギーギャップとアニーリング時間
Garnerone et al. 2012では、を生成するモデルとしてBarabasi & Albert, 1999やBollobas et al., 2001の"Preferential attachment model"とKleinberg et al., 1999の"Copying model"の両方をインスタンスとして、エネルギーギャップをハイパフォーマンスコンピューティングで計算しました。その結果が以下の図です。
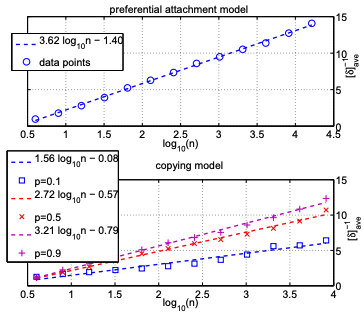
縦軸にエネルギーギャップの逆数、横軸にとしています。上図がPreferential attachment model, 下図がCopying modelでの結果です。この結果からエネルギーギャップが
とわかります。このことと断熱定理より、求めたい終状態へ到達するためにかかるアニーリング時間は
となります。ここでは小さい正の整数です。
古典と比べてどのくらい高速化したか?
この問題を解くときに、古典アルゴリズムで最速であるのはMarkov Chain Monte Carlo(MCMC)法です。この方法を用いるとページランクベクトルを算出するのにかかるステップ数は]であることが知られています。このアルゴリズムでは
のランダムウォーカーが各ページから出発します(すなわち、総ウォーカー数は
)。各ステップ毎に隣あうページ間で情報のやりとりをするために
]ビットが必要です。
]ステップ後に、各ページにウォーカーが何名訪れたかを計算することで、それがページランクとなります。よって古典アルゴリズムでこの問題を解くのに必要なコストは
]であることがわかります。
(1)式と比較すると、量子アニーリングによるページランクアルゴリズムの方が高速化されていることがわかります。
結言
日本人が生活する上で欠かせない技術となったGoogle検索、その背景にある検索エンジンのページランク付けアルゴリズムとそれを断熱量子計算で高速化できるということをご紹介しました。
参考文献
*1:可約グラフとは、可約行列が作るようなグラフのことです。可約行列は
のように、ある巨大な行列のなかに零行列が存在するようなものです。それに関連してある行列が作るグラフが強連結である時、その行列を既約行列(irreducible)と呼びます。既約でない行列を可約と呼びます。さらに補足すると、強連結とは以下のグラフのように任意の2点間に有向路が存在するようなグラフです。>
