この記事の概要
この記事はKhan et al., 2019, "K-Means Clustering on Noisy Intermediate Scale Quantum Computers"を読んだので、その理解を深めるためのアウトプットとして作成したものです。
この論文の概要
以下に示す話題でのアルゴリズムをIBMQX2クラスタリングを行い、どのアルゴリズムが有用であるかを調べたものです。
関連した話題
基本的な量子K-Means法
こちらの記事を参照jijtech.hatenablog.com
距離指標に基づいた分類器
基本的な実装
こちらの記事を参照jijtech.hatenablog.com
量子回路の最適化
この距離指標に基づいた分類器(Distance-based classifier)の量子回路のdepthを減らす方法をご紹介します。4量子ビットでの実装を例に考えてみましょう。
まず以下のような量子状態を準備します。
ここでは分類分けしたい入力データの量子状態、そして
は教師データの量子状態です。補助量子ビットの
の状態とそれぞれをエンタングル状態にしておきます。さらに
を座標変換などを施したあとの入力データと教師データの量子状態としたとき、各々のベクトルの偏角を
とすると
が成り立つならば
のような状態も分類分けには有効であるはずです。よって、量子回路のdepthが少なくても、さえ作り出せれば良いことがわかります。これを叶える量子ゲート群を以下に示します。
ここでは分類分けしたい入力データベクトル、
はそのコピー、そして
はそれぞれ2つのクラスター重心ベクトルです。このゲート群で分類分けができるのかどうかを簡単に確認するために、以下の例を考えましょう。
- 教師データベクトル1: x軸から
回転した方向のベクトル
- 教師データベクトル2: x軸から
回転した方向のベクトル
- 分類分けしたい入力データベクトル: x軸から
回転した方向のベクトル
上述のベクトルの方向関係を図示すると以下のようになります。
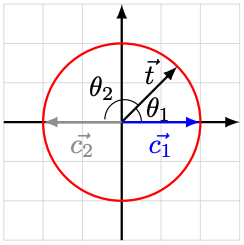
この図と等価となるようなゲート群であることを見てみましょう。
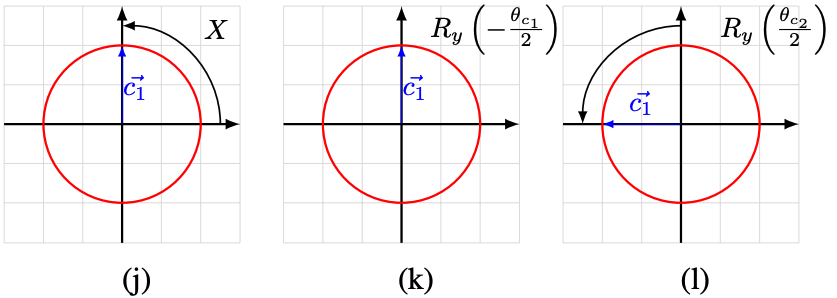
まずはを考えます。
から
だけ回転させます。次に
ゲートを作用させて
に対してベクトルを反転させます。さらに
だけ回転させて、最終的な
を得ます。
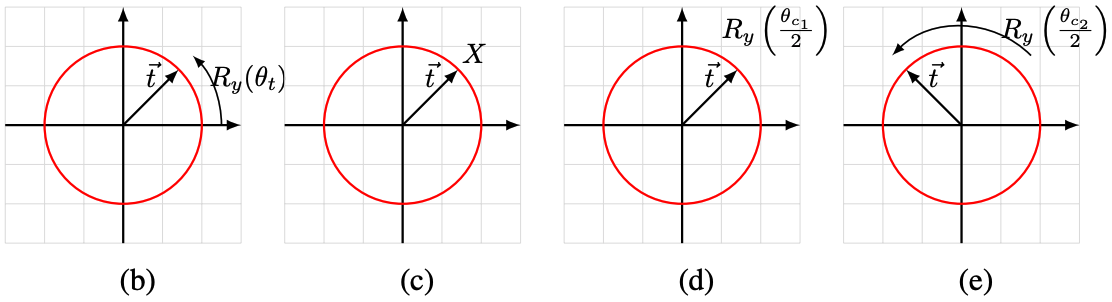
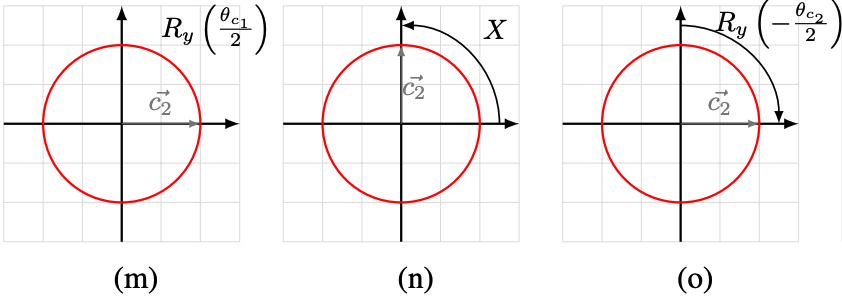
についても考えましょう。
からスタートして、まずは
だけ回転します。
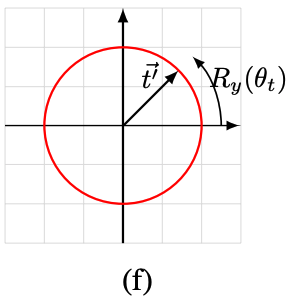
次にだけ回転し、その後
で反転します。最後に
だけ回転させて、最終的な
を得ます。
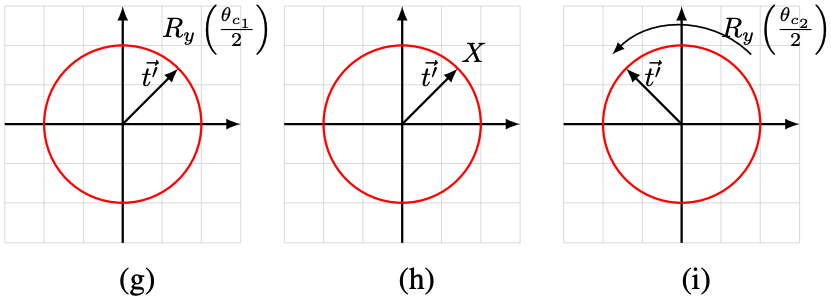
続いてです。
は最初に
で反転させます。次に
回転させて最終的な
を得ます。
最後にを見ましょう。
回転した後に、
で反転させます。そして
回転させれば、最終的な
を得ます。
最終的なの方向関係は以下のようになります。
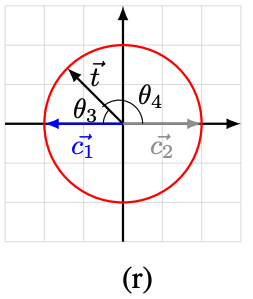
このときとなり、このゲート郡でも正しく分類できることがわかります。
以上の議論から、最適化されたdistance-based classifierの量子回路は以下のようになります。

Negative Rotations
基本構成
この手法は、分類わけしたい入力データから一番近い重心を見つけるために、量子ビットを負方向(あるいは正方向)に回転させます。
ある入力データのベクトルと2つの分類重心
があるとします。どちらの重心がベクトルに近いかを求めてみましょう。入力データ・1つ目の重心・2つ目の重心の偏角をそれぞれ
とすると、
の方が近い場所にあるとき
の関係が成り立ちます。
ここで量子ビットの状態を考えましょう。これらを先ほどの重心に対するメトリックと考えます。すなわち
が測定される確率が高い事象を、片方の重心に近い状態というようにします。2つのベクトルのなす角の最大値は180度なので、一般に
が成り立ちます。よってによって
だけ回転させたのちに、
によって
だけ回転させれば、重心とのなす角を90度以下にすることができます。
これをの2つの重心がある場合に分類分けする量子回路を示すと以下のようになります。
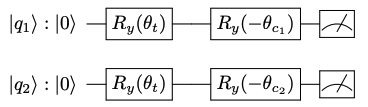
2つの量子ビットのうちで
が測定される確率が高ければ重心
に近く、
で
が測定される確率が高ければ重心
に近いことがわかります。
これを一般に、n個の入力データをk個のクラスターに分類したい場合は以下のような量子回路を用います。
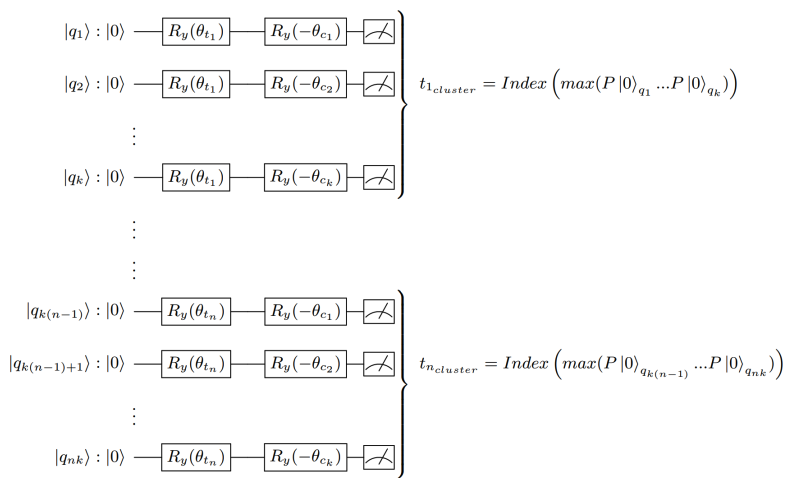
1つのデータにつき、k個のクラスター重心のうちどれに近いかどうかを判断するためにk個の量子ビットが必要になります。よって必要な量子ビットの総数はnk個となります。
Negative Rotationの利点と欠点
上図からわかるように、このアルゴリズムでは分類したいクラスターの数が増えてもdepthは変化しません。しかし、必要な量子ビット数、すなわちwidthが線形で大きくなるというデメリットがあります。
Distance Calculation using Destructive Interference
基本構成
2つのベクトルのユークリッド距離を計算すると
となります。ここで
という量子ビットの状態を考えましょう。ここではそれぞれ
です。この状態にアダマールゲートを作用させましょう。
よって最初の量子ビットを測定すると、の状態が得られる確率は
となります。これより
です。よってを最初に作成すれば良いことがわかります。
これを実現する量子回路を以下に示します。
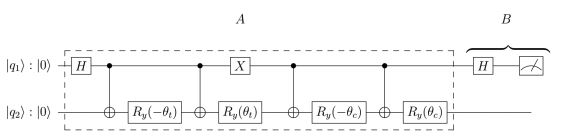
の状態
と入力データ
をエンタングルさせます。その後、
の状態
とクラスターの重心
をエンタングルさせます。
K-Means法によってk個のクラスターに分類したい場合、ある入力データとk個のクラスター重心との距離を計算します。そしてそれらの最小となる要素を選出することで、入力データが含まれるクラスターを同定します。
この手法の利点
すでに提案されている量子K-Means法ではの両方を同時に用意する必要がありました。しかしこの手法では測定前の最後の状態
のみ準備すれば良いので、比較すると簡単です。またSwapTestの必要がなくなったため、その分の量子演算回数を減らすことができます。
数値実験
使用したデータ
以下にテストデータとして用いたものを示します。
- ランダムに生成したデータセット
- Irisデータセット
- MNISTデータセット
実験結果
以下にIBMQX2による実験結果と、比較として古典コンピュータ上でのScikit-learnでのK-Means法の結果を示します。
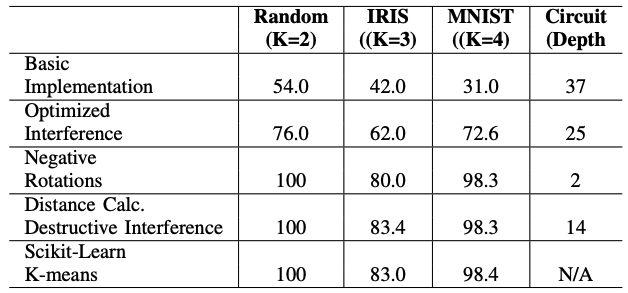
上から順に、1. 距離指標に基づいた分類、2. 距離指標分類の量子回路を最適化したもの、3. Negative Rotation、4. Distance Calculation using Destructive Interference、5. 古典によるScikit-learn K-Meansの結果です。数値実験の結果、Negative RotationとDistance Calculation using Destructive Interferenceによる実装が少ないdepthで良い精度を出せていることがわかりました。
古典と比べてどのくらい速いのか?
この論文によればNegative Rotationの計算量は、Distance Calculation using Destructive Interferenceの計算量は
です。Negative Rotationは少ないdepthで良い精度が達成できているのに対して、線形高速化しか達成できていません。しかしDistance Calculation using Destructive Ingerferenceは指数で高速化が達成されています。
結言
今回は様々な量子K-Means法アルゴリズムをNISQデバイスに実装し、それを実際に実行した結果をご紹介しました。